数据库范式
最后一次更新时间:Monday, February 1st 2021, AM
第零范式(无范式)
如下所示
第一范式(1NF)
字段(列)是原子的,不可再分的
把第零范式中的重复字段抽取出来,减少冗余。来看下边的示例:

上图中,字段 进货 与 销售 并不是原子的,改为如下图所示即符合第一范式规范。

再看一个完整的第一范式数据表示例: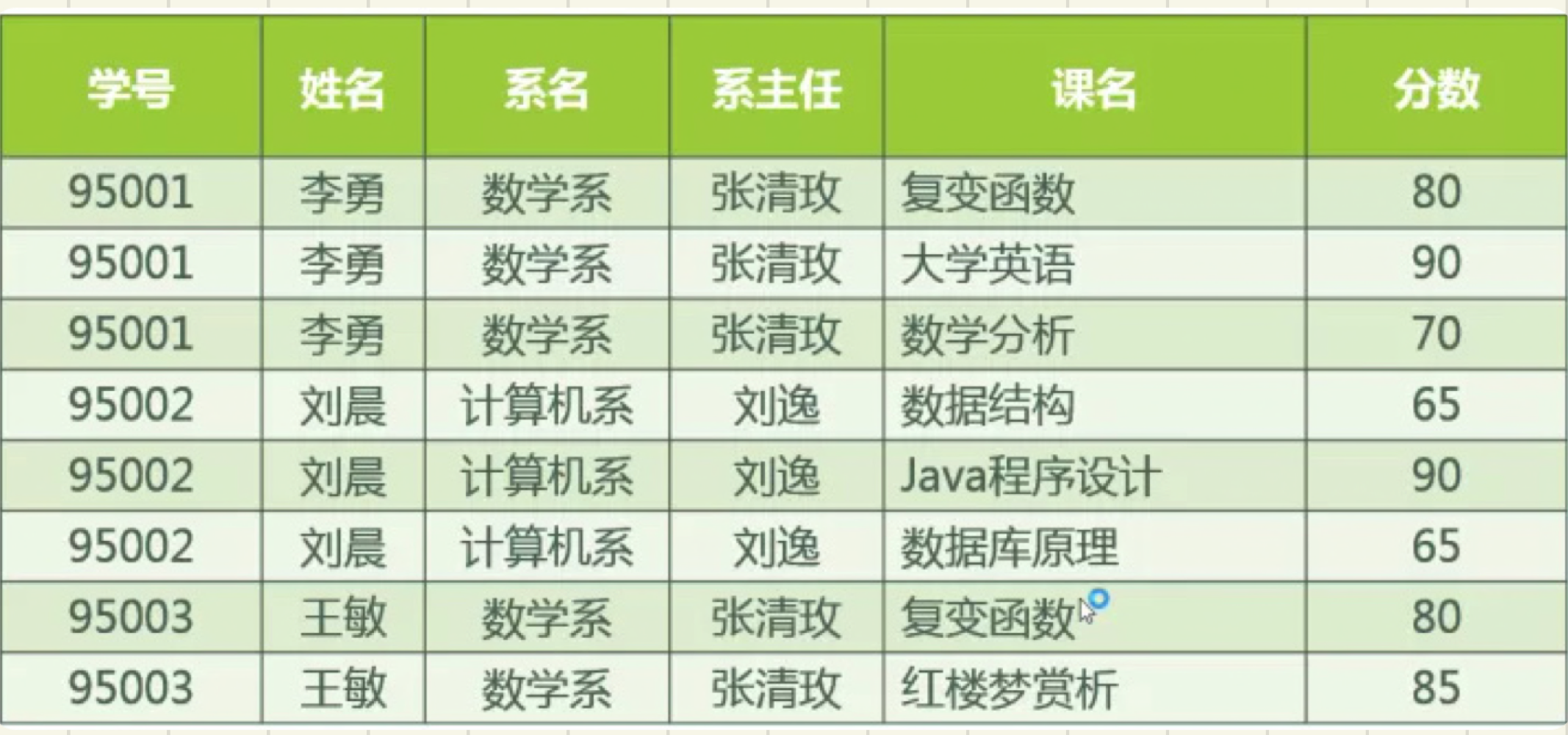
第一范式的缺点:冗余过大,且容易导致异常(插入异常、删除异常、修改异常)。
- 插入异常:假如学校新建了一个系,但是暂时还没有招收任何学生。那么,无法将系名与系主任的数据单独地添加到数据表中。
- 删除异常:假如将某个系中,所有学生相关的记录全部删除,那么所有系与系主任的数据也会随之消失(系中没有学生不代表这个系也没了)。
- 修改异常:假如小明转到法律系,那么为了保证数据库中数据的一致性,需要修改三条记录中系与系主任的数据。
第一范式是关系型数据库需要满足的最低标准。
第二范式(2NF)
对于第二范式,最关键的点在于主键。
第二范式要求每一行可被唯一区分,通常解决方法是加上一列ID,并作为主键。并且相比于1NF,2NF需要消除表中的部份依赖,常用的办法是将大表拆分为多个小表。
将之前的1NF示例改造成2NF,则如下图的两张数据表所示: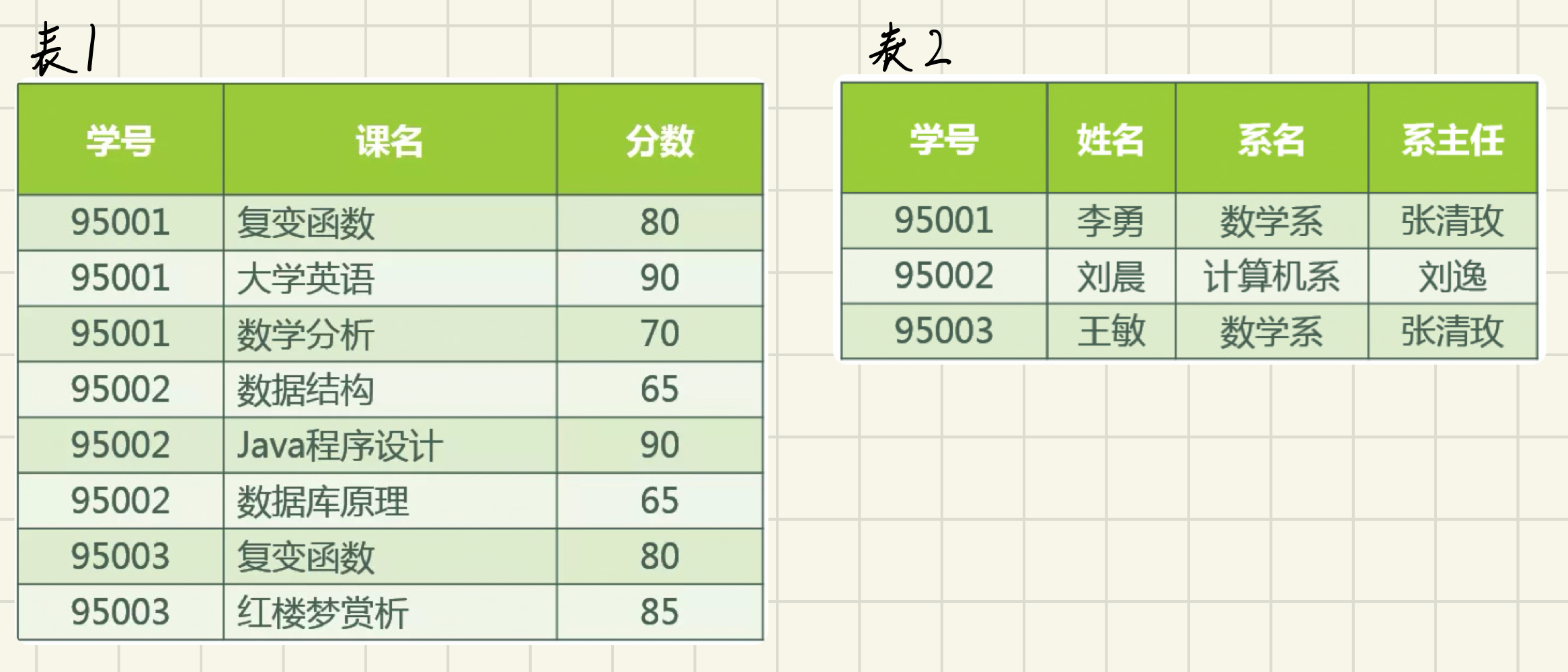
第二范式的缺点:插入异常和删除异常依然存在。
- 数据冗余:学生姓名、系名、系主任 不再像之前一样重复那么多次了。(有改进)
- 修改异常:小明转到法律系,只需要修改一次小明对应的系的值即可。(有改进)
- 插入异常:若要插入一个尚无学生的新系的信息,由于学生表(表一)中,主键是学号(不能为空),所以是非法操作。(无改进)
- 删除异常:删除某个系中所有的学生记录,该系的信息仍全部丢失。(无改进)
第三范式(3NF)
对于第三范式,最关键的点在于外键。
相比于2NF,3NF消除了非主属性(对于码的传递函数依赖)。
传递依赖:若 x -> y, y -> z 则 x -> z。
将上述示例改为3NF,如下图所示: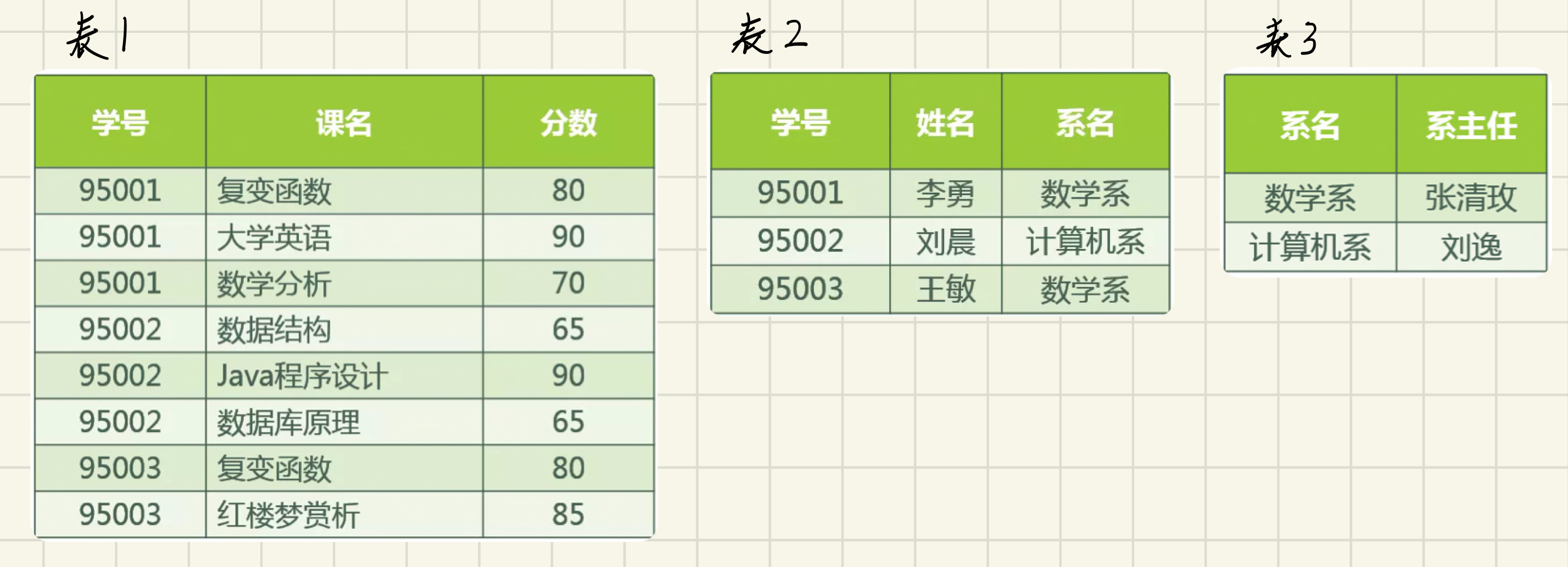
- 数据冗余:进一步减少了冗余。(有改进)
- 插入异常:插入一个尚无学生的新系,在表3中增加记录即可,三张表相互独立无影响。(有改进)
- 删除异常:删除一个系中所有学生记录,原理同上,该系的信息不会丢失。(有改进)
除特别声明外,本站所有文章均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
